

Medium
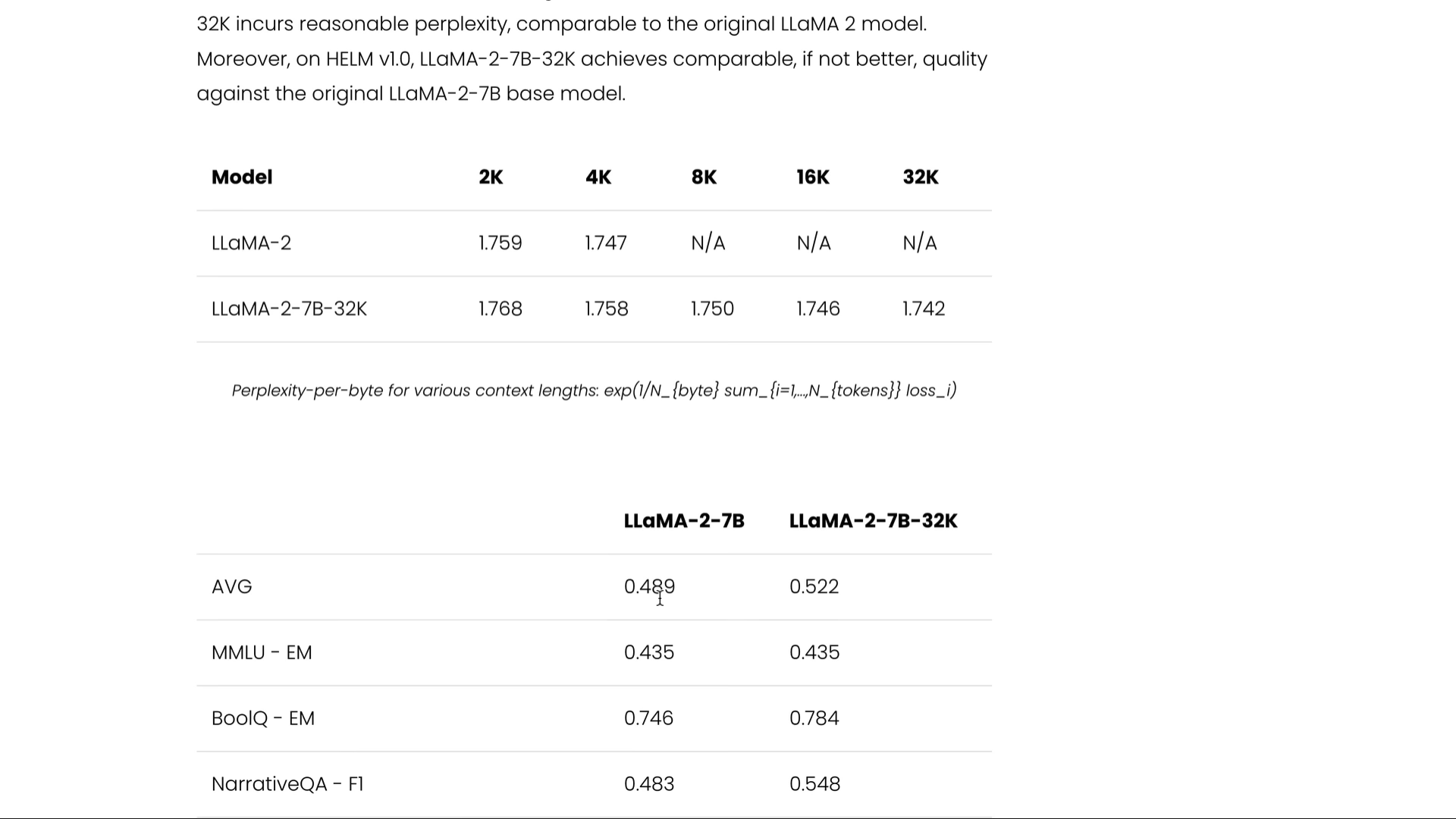
Im referencing GPT4-32ks max context size The context size does seem to pose an issue but Ive devised a cheap solution I was thinking why not 1 take in the message with. A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. SuperHot increased the max context length for the original Llama from 2048 to 8192 Can people apply the same technique on Llama 2 and increase its max context length from 4096 to. All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1 Llama 2 encompasses a series of. LLaMA-2 has a context length of 4K tokens To extend it to 32K context three things need to come together..
Lets Build the Local Chatbot Heres a hands-on demonstration of how to create a local. Lets go step-by-step through building a chatbot that takes advantage of Llama 2s large context. The objective is to build a chatbot using a quantized version of Metas Llama2 7B parameters. How to Build a Local Chatbot with Llama2 and LangChain In this tutorial well walk through building. Next make a LLM Chain one of the core components of LangChain. We can rebuild LangChain demos using LLama 2 an open-source model. In particular the three Llama 2 models llama-7b-v2-chat llama-13b-v2-chat and llama-70b-v2..
Medium
All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1 Llama 2 encompasses a series of. With Microsoft Azure you can access Llama 2 in one of two ways either by downloading the Llama 2 model and deploying it on a virtual machine or using Azure Model Catalog. LLaMA-2-7B-32K is an open-source long context language model developed by Together fine-tuned from Metas original Llama-2 7B model This model represents our efforts to contribute to. Some differences between the two models include Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters Llama 2 was trained on 40 more. The Llama 2 release introduces a family of pretrained and fine-tuned LLMs ranging in scale from 7B to 70B parameters 7B 13B 70B..
Chat with Llama 2 70B Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or even name your. This release includes model weights and starting code for pretrained and fine-tuned Llama language models Llama Chat Code Llama ranging from 7B to 70B parameters. Experience the power of Llama 2 the second-generation Large Language Model by Meta Choose from three model sizes pre-trained on 2 trillion tokens and fine-tuned with over a million human. Llama 2 7B13B are now available in Web LLM Try it out in our chat demo Llama 2 70B is also supported If you have a Apple Silicon Mac with 64GB or more memory you can follow the instructions below. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters This is the repository for the 7B pretrained model..

Comments